IBM: come cambia l'offerta storage
 Redazione ImpresaCity
Redazione ImpresaCity IBM riorganizza l'offerta storage in funzione dei casi applicativi più comuni e richiesti. Grazie anche a una partnership con Cohesity.



Rispetto alle evoluzioni sinergiche con Red Hat, alle attività dei laboratori di ricerca e allo zoccolo duro mainframe, l'anima storage di IBM appare sempre un po' in secondo piano. Eppure anche in questo campo ci sono lavori ed evoluzioni in corso, perché anche il mondo storage sta cambiando e perché, nel caso specifico di IBM, Red Hat ha portato in dote diverse tecnologie software che man mano stanno integrandosi con le componenti IBM. Ceph, in questo senso, sta diventando la base tecnologica dell'approccio IBM al Software-Defined Storage.
C'è insomma abbastanza carne al fuoco da dover mettere ordine in una offerta in cui, anche prima della fusione con Red Hat, non era semplicissimo orientarsi. La prima mossa che IBM ha deciso di fare è di branding: il marchio IBM Spectrum diventa più semplicemente IBM Storage, per dare maggiore importanza al concetto stesso di storage e anzi - spiega Denis Kennelly, General Manager, IBM Storage - "rendere evidente che IBM è ancora molto impegnata nel comparto storage". Parallelamente, IBM intende semplificare la sua offerta riducendo il numero di prodotti e presentandoli in una ottica orientata alle soluzioni, più che ai prodotti in sé. Soluzioni che dal punto di vista dei clienti, spiega ancora Kennelly, "sono software-defined, aperte e utilizzabili come servizio".
Cambiare l'etichetta dello storage IBM insomma non basta, ovviamente, e l'obiettivo è allineare l'offerta con le principali esigenze espresse dagli utenti. Che per IBM vanno in tre direzioni principali: supporto delle applicazioni di AI e HPC, supporto del multicloud ibrido, protezione dei dati in generale.
Nel primo ambito IBM vede la necessità, per lo storage, di supportare applicazioni che sempre più spesso generano workload di intelligenza artificiale, machine learning, High Performance Computing. Questo ovviamente impone nuovi requisiti a tutto il flusso di gestione dei dati, che va dalla fase di ingresso a quella di aggregazione e infine a quella di analisi. Per gestire bene questo flusso IBM si focalizza ora su tre componenti base.
Lato software, IBM Storage Ceph opera come piattaforma storage software-defined unificata, open source, dedicata ai workload generici e alla gestione dello storage a blocchi, a file, a oggetti. IBM Storage Scale è invece una piattaforma storage a file e a oggetti dedicata in modo specifico ai workload più esigenti: AI, ML, HPC. "Sotto" alla parte software c'è la componente hardware degli IBM Storage Scale System, ossia i precedenti IBM Elastic Storage System: appliance convergenti di computing e storage in configurazioni all-flash e ibride.
Nello sviluppo di una offerta storage è impossibile non considerare che la maggior parte delle aziende utenti ha già intrapreso, o potrebbe decidere di farlo, la strada del multicloud ibrido. Che oltretutto per la nuova IBM è quasi un presupposto filosofico. Containerizzazione e gestione dei dati in ambienti distribuiti non sono, però, sempre andati molto d'accordo e hanno richiesto lo sviluppo di piattaforme di Software-Defined Storage e data orchestration che riuscissero a portare i dati là dove le applicazioni virtualizzate lo richiedevano. Un'esigenza che nel tempo si è amplificata, non ridotta.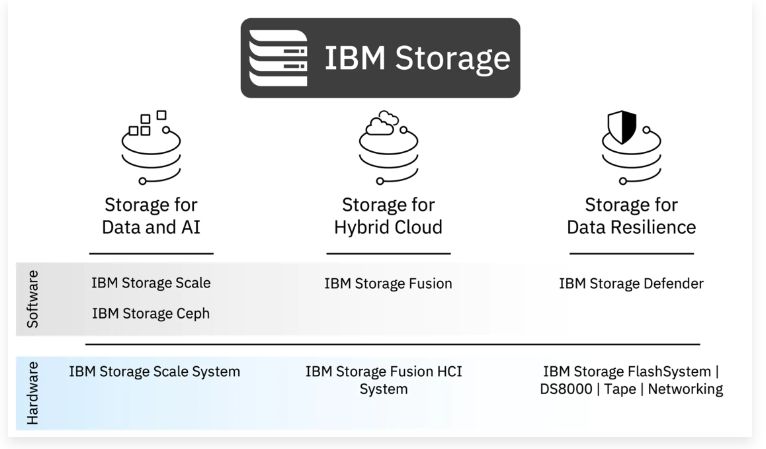
Nella rinnovata offerta IBM storage questo ruolo viene svolto, lato software, da IBM Storage Fusion. È l'erede diretto di Spectrum Fusion SDS e si occupa di tutte le operazioni di data orchestration necessarie in ambienti Red Hat OpenShift. Per chi preferisce una soluzione integrata hardware/software ci sono i sistemi IBM Storage Fusion HCI System: in un rack, tutto quello che serve per realizzare ambienti Kubernetes con la relativa gestione dei dati.
Trasversalmente a qualsiasi applicazione collegata con lo storage c'è sempre la necessità di proteggere le informazioni, di raggiungere quella che IBM chiama "data resiliency by design". In questa concezione i dati vanno protetti da tutti i possibili rischi, che spaziano dagli errori umani ai data breach sino agli attacchi mirati stile ransomware. Per contenere questi rischi, secondo IBM, servono componenti di machine learning e automazione che rilevino minacce o anomalie e mettano subito in atto azioni di difesa e ripristino.
IBM per questo ha sviluppato una nuova piattaforma che ha battezzato IBM Storage Defender e che deriva anche da una collaborazione con Cohesity. Quest'ultima ha portato le sue competenze per la protezione dei dati in ambienti cloud e ibridi, nello specifico portando in Storage Defender la sua soluzione Cohesity DataProtect. IBM si è invece occupata della protezione dei dati per i server fisici e virtuali (con IBM Storage Protect, già IBM Spectrum Protect), del supporto agli ambienti containerizzati (con il già citato IBM Storage Fusion) e soprattutto della parte hardware. Come soluzione, IBM Storage Defender comprende infatti come componenti preferenziali i sistemi IBM Storage FlashSystem, all-flash o di hybrid storage.
 Rimani sempre aggiornato, seguici su Google News!
Seguici
Rimani sempre aggiornato, seguici su Google News!
Seguici
Notizie correlate













Speciali Tutti gli speciali
Calendario Tutto
Magazine Tutti i numeri

G11 Media Networks
ImpresaCity e' un canale di BitCity, testata giornalistica registrata presso il tribunale di Como ,
n. 21/2007 del
11/10/2007- Iscrizione ROC n. 15698
G11 MEDIA S.R.L.
Sede Legale Via NUOVA VALASSINA, 4 22046 MERONE (CO) - P.IVA/C.F.03062910132
Registro imprese di Como n. 03062910132 - REA n. 293834 CAPITALE SOCIALE Euro 30.000 i.v.
